CRISP-DM, Metodología de Datos

Si, existe una Metodología para el Data Science, para la Ciencia de Datos, y esto no es nuevo, la que veremos hoy nació en los 90s, cuando se usaba el termino KDD (Knowledge Discovery in Databases)
Nota: KDD (Knowledge Discovery from Databases), es el proceso que se encarga de sacar conclusiones o información “limpia” a partir de unos datos que generalmente están organizados en una base de datos.
Este proceso es iterativo debido a que la salida de algunas de sus fases puede requerir que se vuelva a una fase anterior y también a que en ocasiones es necesario realizar varias iteraciones para poder extraer conocimiento de los datos. KDD, todo un tema para un Post posterior…
Regresando a CRISP-DM…
La CRISP-DM (Cross Industry Standard Process for Data Mining) incluye un modelo y una guía, estructurados en seis fases, algunas de las cuales son bi-direccionales, es decir que de una fase en concreto se puede volver a una fase anterior para poder revisarla, por lo que la sucesión de fases no tiene porqué ser ordenada desde la primera hasta la última.
CRISP-DM, la historia
CRISP-DM fue concebido a fines de 1996 por tres «veteranos» del mercado de minería de datos. DaimlerChrysler (entonces Daimler-Benz) ya tenía experiencia, por delante de la mayoría de las organizaciones industriales y comerciales, en la aplicación de minería de datos en sus operaciones comerciales.
SPSS (entonces ISL) había brindado servicios basados en minería de datos desde 1990 y había lanzado el primer banco de trabajo de minería de datos comercial, Clementine, en 1994. NCR, como parte de su objetivo de brindar valor agregado a sus clientes de almacenamiento de datos de Teradata, había establecido equipos de consultores de minería de datos y especialistas en tecnología para atender los requerimientos de sus clientes.
CRISP-DM, Metodologia
CRISP-DM integra todas las tareas necesarias en los proyectos de minería de datos, desde la fase de comprensión del problema hasta la puesta en producción de sistemas automatizados analíticos, predictivos y/o prospectivos.
La Metodología está compuesta por seis fases, el cual dependen entre sí, tanto en secuencia o de forma cíclica, pudiendo tener interacciones que permitan mejorar la aproximación obtenida en otras fases anteriores.
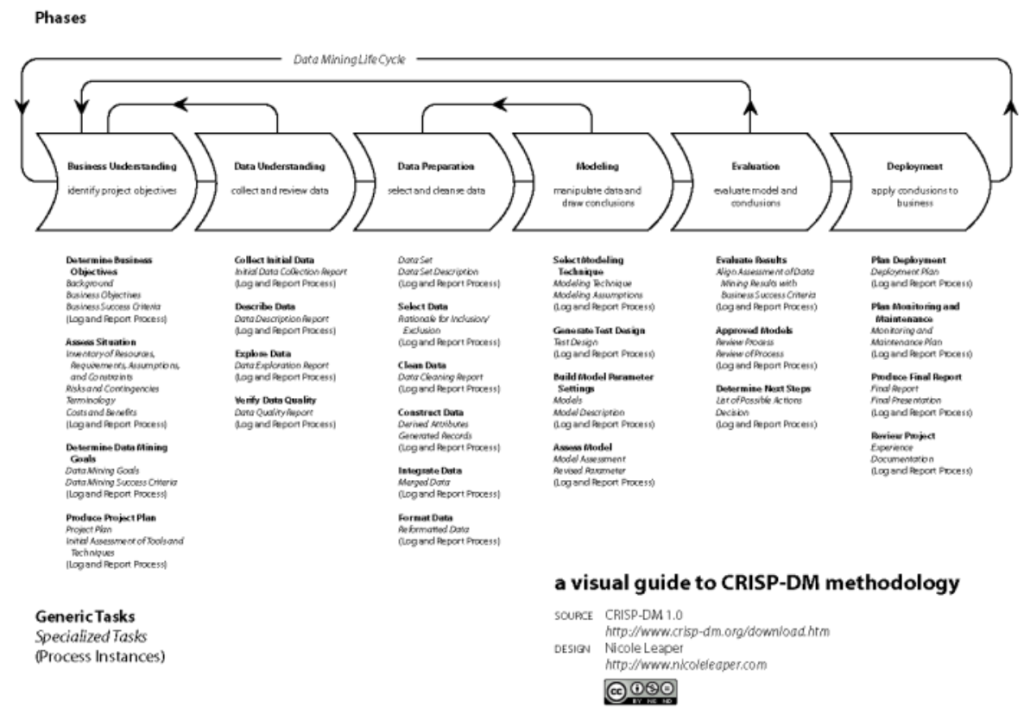
CRISP-DM, Las Fases
Las fases de la Metodología son:
Pueden ser una tras de otra, pero el orden de loas fases no alterarían la misma
Comprensión del Negocio
Se establece cuáles serán los criterios para medir el éxito en el proyecto, ya sean de tipo cualitativo o cuantitativo. Después se realiza una evaluación de la situación actual determinando los antecedentes y requisitos del problema, tanto en términos de negocio como de minería de datos.
Y por último, se realiza un Plan de Proyecto donde se tendría en cuenta qué pasos se deben seguir y qué procedimientos se emplearán en cada uno de ellos.
El inicio de cada proyecto inicia comprendiendo a profundidad el problema que se quiere resolver y estableciendo los requisitos y objetivos del mismo, desde una perspectiva empresarial para luego trasladarlos a objetivos técnicos y después a un Plan de Proyecto.
Esta primera fase es probablemente la más importante y agrupa las tareas de comprensión de los objetivos y requisitos del proyecto desde una perspectiva de negocio, con el fin de convertirlos en objetivos técnicos y en un plan de proyecto.
Comprensión de los datos
Desarrollar tareas:
–Primero, recolectar datos iniciales y adaptarlos a las necesidades del proyecto para su posterior procesamiento.
–Segunda, describir formalmente los datos obtenidos: número de instancias (filas) y atributos (columnas), el significado de los atributos y una descripción rigurosa del formato de los datos.
–Tercero, explotar los datos aplicando técnicas básicas de estadística descriptiva que revelan propiedades de estos.
–Cuarto, llevar a cabo una verificación de los datos para determinar su consistencia, la cantidad y distribución de los valores nulos o valores fuera de rango que puedan provocar ruido en el modelado posterior.
Esta fase comprende la recolección inicial de los datos con el objetivo de establecer un primer contacto con el problema, familiarizarse con ellos, identificar su calidad y establecer las relaciones más evidentes que permitan definir las primeras hipótesis. Esta fase junto a las dos siguientes fases son las que demandan el mayor esfuerzo y tiempo en un proyecto de minería de datos. Por lo general si la organización cuenta con una base de datos corporativa, es deseable crear una nueva base de datos específica para el proyecto de DM (Data Mining), ya que durante el desarrollo del proyecto es posible que se generen frecuentes y abundantes accesos a la base de datos con el fin de realizar consultas y probablemente se produzcan modificaciones, lo cual podría generar muchos problemas.
Preparación de los datos.
Es la fase intermedia para seleccionar, limpiar y generar conjuntos de datos correctos, organizados y prepararlos para la fase de modelado.
Es la fase crítica del proyecto de minería de datos, los errores en los datos que se pasan por alto y que no son resueltos en esta fase, evidentemente se trasladarían hasta la fase de modelado, y por consecuente generaría una reducción en la exactitud de los modelos o incluso, sería imposible entregar al cliente resultados basados en datos que aún contienen errores no detectados.
Se estima que en esta fase consume el 75% del total del tiempo del proyecto, por la demanda en el esfuerzo, análisis, etc.
Esta fase se encuentra relacionada con la fase de Modelado, ya que en función de la técnica de modelado elegida, los datos requieren ser procesados de una manera o de otra, por esta razón las fases de preparación y de modelado interactúan de forma permanente.
Modelado
Seguir una serie de pautas que nos ayudarán a obtener mejores resultados. Aunque parezca obvio, el primer paso es seleccionar los algoritmos de modelado más apropiados al problema.
Posteriormente se genera un plan de prueba, donde configuramos los valores de los parámetros que se usarán para los algoritmos de aprendizaje automático (conocido como el Machine Learning), ya que muchos de estos pueden ser configurados para determinar las características del modelo que se generará. También, se determinan las métricas de evaluación que se calcularán para evaluar la bondad de los modelos.
Luego se construyen los modelos, ejecutando los algoritmos seleccionados sobre los datos preparados con el fin de generar uno o más modelos y calcular las métricas. Para finalizar se evaluan los resultados, donde se analizan las métricas de evaluación obtenidas con el fin de conocer la bondad de los modelos generados y garantizar que cumplan con los criterios de éxito definidos al inicio del proyecto.
En esta fase se lleva a cabo la creación de modelos a partir de los datos suministrados desde la fase anterior.
Estos modelos de conocimiento pueden ser de distintos tipos
Los parámetros utilizados en la generación del modelo dependen de las características de los datos y de las características de precisión qué se quieran lograr con el modelo.
Evaluación
Para esta fase se evalúa el modelo, teniendo en cuenta el cumplimiento de los criterios de éxito del problema, debe considerarse que la fiabilidad calculada para el modelo se aplica solamente para los datos sobre los que se realizó el análisis. Es preciso revisar el proceso, teniendo en cuenta los resultados obtenidos, para poder repetir algún paso anterior, en el que se pueda haber cometido algún error.
Si los modelos obtenidos cumplen con las expectativas de negocio, se continua con la explotación del modelo, si no, se evalúa en esta fase si se vuelve a iterar nuevamente sobre los pasos anteriores con el objetivo de encontrar nuevos resultados.
Para llevar a cabo esto, se debe realiza una evaluación formal de los resultados obtenidos en las fases anteriores del proyecto, teniendo en cuenta los criterios de éxito de negocio y explicando las causas que provocaron los grados de éxito alcanzados y revisando todo el proceso llevado a cabo con el fin de encontrar errores que puedan afectar al éxito.
Se debe considerar que se pueden emplear múltiples herramientas para la interpretación de los resultados. Si el modelo generado es válido en función de los criterios de éxito establecidos en la fase anterior, se procede a la explotación del modelo.
Despliegue
Para esta fase, una vez que el modelo ha sido construido y validado, se transforma el conocimiento obtenido en acciones dentro del proceso de negocio, esto puede hacerse por ejemplo cuando el analista recomienda acciones basadas en la observación del modelo y sus resultados, o por ejemplo aplicando el modelo a diferentes conjuntos de datos o como parte del proceso.
Generalmente un proyecto de minería de datos no concluye en la implantación del modelo, ya que se deben documentar y presentar los resultados de manera comprensible para el usuario con el objetivo de lograr un incremento del conocimiento. Por otra parte, en la fase de explotación se debe asegurar el mantenimiento de la aplicación y la posible difusión de los resultados.
CRISP-DM, infografía
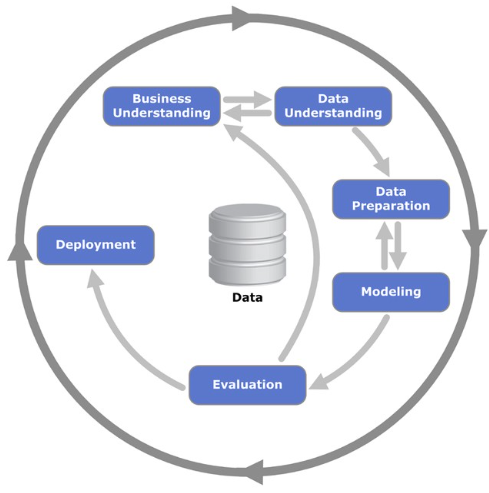
CRISP-DM, La Guia
El consorcio que planteó CRISP-DM se disolvió hace unos años, pero CRISP-DM es la Metodología que mas se utiliza en los proyectos de análisis de datos y que abordar con mas seriedad el análisis de los mismos, dandole un orden y calidad en los resultados. esperados.
IBM tiene un extracto de La Guía: IBM y KDE donde puedes bajar el PDF
Conclusión
- CRISP-DM como una adaptación de la Metodología tradicional de gestión de proyectos al contexto de la ciencia de datos, que bien se podría adaptar aun Agile o un DevOps.
- Es una metodología bastante clara en el sentido de que las fases estan muy bien marcadas, en otro Post abordare las tarea que se tienen en cada Fase.
- El tipo de resultados están definidos, reduce la incertidumbre del proyecto, reduce la complejidad y contribuye a que el cliente tenga una mayor comprensión y control de todo el proceso.
- Es muy probable que la gestión de las fases les resulte muy familiar porque se asemeja a la que esté llevando en otros proyectos no relacionados con datos, es decir, es muy adaptativa.
Fuentes de información para el presente Post: CRISP-DM, IBM, KDE
Visita: Glosario de Términos Big Data | ¡Se actualiza día con dia!
Síguenos en las Redes Sociales y ahora en todos los canales de Podcasts, para obtener actualizaciones periódicas y opiniones sobre lo que está sucediendo en el mundo de Project Manager, Agile, Big Data, Cloud, Scrum y mas…
Busca iPMOGuide en Facebook | X | LinkedIn | Pinterest | Podcast
Nos leemos pronto, ¡un abrazo!